Linear Regression
4 things to take in consideration:
Dataset:
(, ) with being the feature and being the target.
Model:
represented by the function , and being the parameters.
Cost Function:
A function to compute the error between the predicted values and the targets.
In our case, , being the number of rows.
Minimisation Algorithm:
In our case, we are going to use the Gradient Descent.
Basically, for each parameter , we compute = - .
being the learning rate.
Transform this to a problem using matrices
Let's is the number of features, is the number of rows.
= thus =
=
And the parameters =
Finally we get the model
As for the cost function
As for the gradient
Thus
import numpy as np
from sklearn.datasets import make_regression
x, y = make_regression(n_samples=100, n_features=1, noise=10) # Here m=100 and n=1
y = y.reshape(y.shape[0], 1)
x.shape, y.shape
((100, 1), (100, 1))
import matplotlib.pyplot as plt
plt.scatter(x, y)
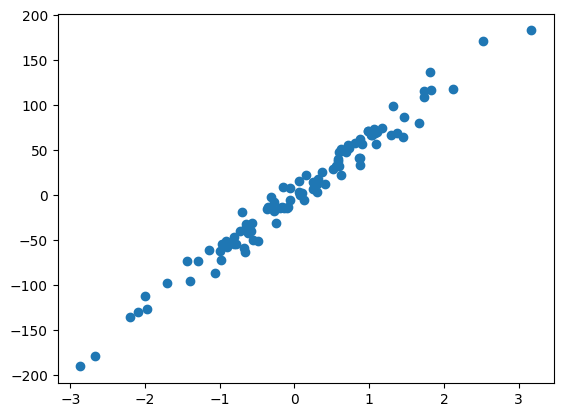
X = np.hstack((x, np.ones((x.shape[0], 1))))
X.shape
(100, 2)
theta = np.random.randn(X.shape[1], 1)
theta
array([[-1.11140959],[ 0.15718568]])
def model(X, theta):
return X.dot(theta)
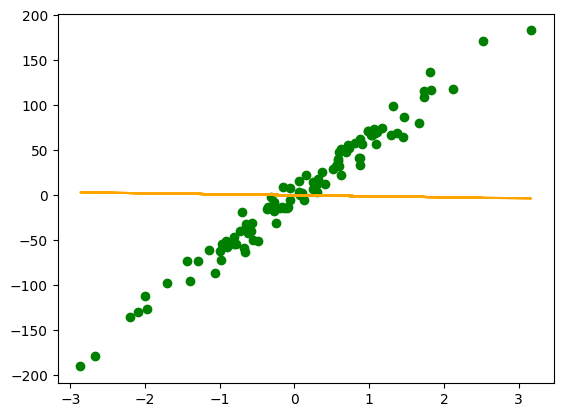
plt.scatter(x, y, c='g')
plt.plot(x, model(X, theta), c='orange')
def cost_function(theta, X, y):
return 1 / (2 * len(y)) * np.sum((X.dot(theta) - y) ** 2)
cost_function(theta, X, y)
2466.3199193827004
def gradients(theta, X, y):
return 1 / len(y) * X.T.dot(X.dot(theta) - y)
gradients(theta, X, y)
array([[-76.34230311], [ -4.87819021]])
def gradient_descent(theta, X, y, learning_rate, n):
for i in range(n):
theta = theta - learning_rate * gradients(theta, X, y)
return theta
final_theta = gradient_descent(theta, X, y, 0.01, 1000)
plt.scatter(x, y, c='g')
plt.plot(x, model(X, final_theta), c='orange')
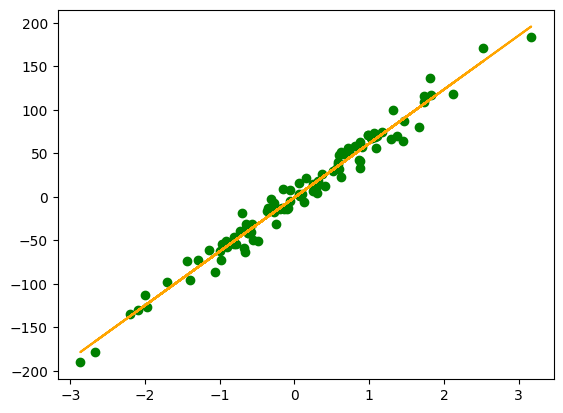
And there you have it, we have created a linear model that represents our data!
Now, let's study the learning process.
Let's visualize the cost function's variation, and the linear model variation!
def gradient_descent_v2(theta, X, y, learning_rate, n):
costs = []
thetas = []
for i in range(n):
theta = theta - learning_rate * gradients(theta, X, y)
costs.append(cost_function(theta, X, y))
thetas.append(theta)
return {"theta": theta, "costs": costs, "thetas": thetas}
result = gradient_descent_v2(theta, X, y, 0.01, 1000)
plt.plot(range(1000), result["costs"])
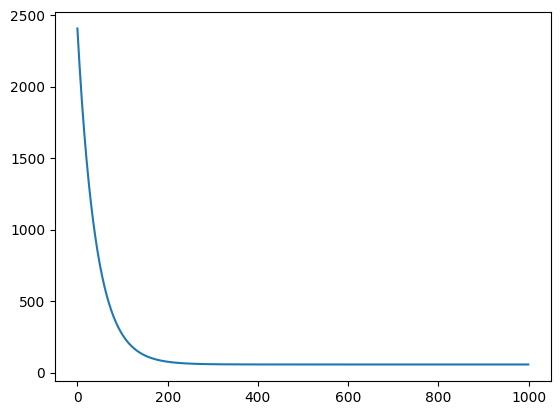
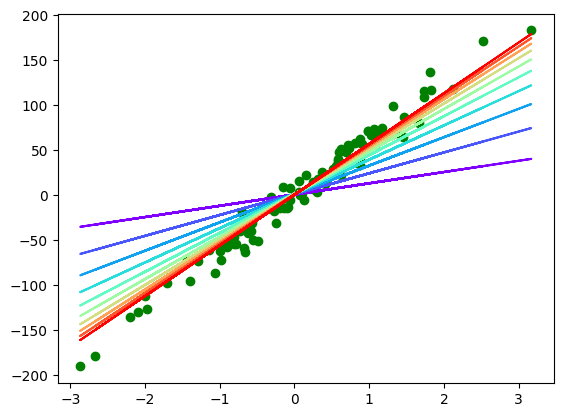
plt.scatter(x, y, c='g')
color = iter(plt.cm.rainbow(np.linspace(0, 1, 10)))
for i in range(10):
c = next(color)
plt.plot(x, model(X, result["thetas"][i * 100]), c=c)
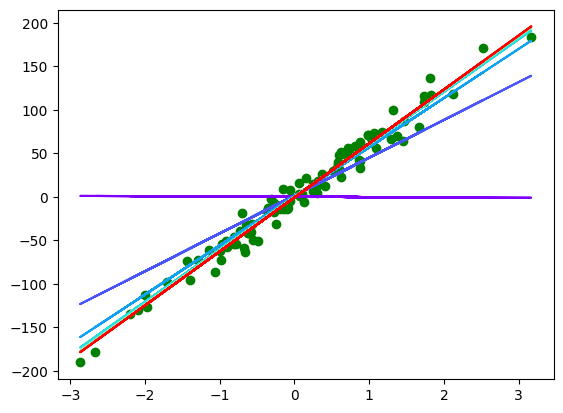
What we can conclude is is sufficient to train the model. Let's test it!
result = gradient_descent_v2(theta, X, y, 0.01, 200)
plt.plot(range(200), result["costs"])
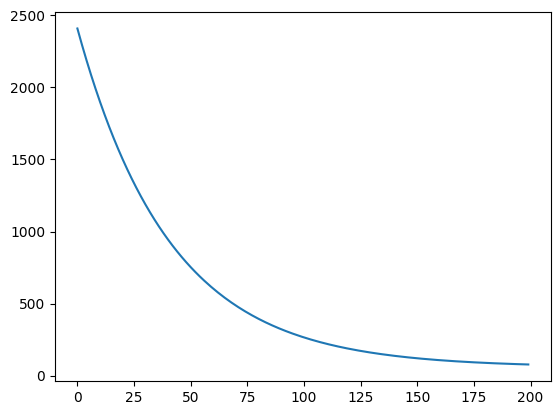
plt.scatter(x, y, c='g')
color = iter(plt.cm.rainbow(np.linspace(0, 1, 10)))
for i in range(10):
c = next(color)
plt.plot(x, model(X, result["thetas"][i * 20 + 19]), c=c)